5 Presenting the Evidence (Summarizing Data)
If you open any search engine and look up “data visualization,” you will quickly be overwhelmed by a host of pages, texts, and software filled with tools for summarizing your data. Here is the bottom line: a good visualization is one that helps you answer your question of interest. It is both that simple and that complicated.
ImportantFundamental Idea III
Using data for decision-making requires summarizing and visualizing the distribution of the data towards addressing the research objective.
Whether simple or complex, all graphical and numerical summaries should help turn the data into usable information. Pretty pictures for the sake of pretty pictures are not helpful. In this chapter, we will consider various simple graphical and numerical summaries to help build a case for addressing the question of interest. The majority of the chapter is focused on summarizing a single variable; more complex graphics are presented in future chapters within a context that requires them.
5.1 Characteristics of a Distribution (Summarizing a Single Variable)
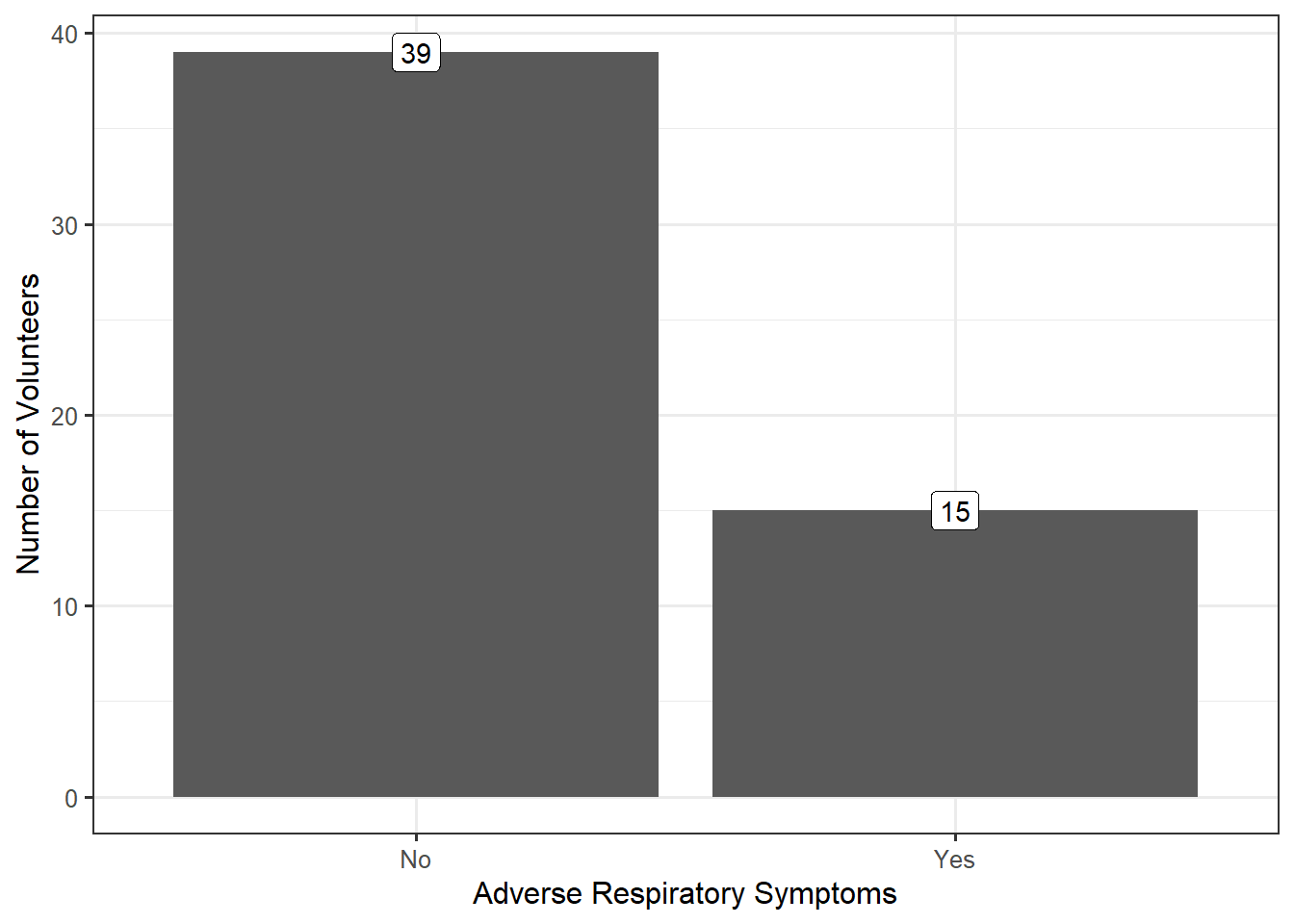
Remember that because of variability, the key to asking good questions is to not ask questions about individual values but to characterize the underlying distribution (see Definition 3.3). Therefore, characterizing the underlying distribution is also the key to a good visualization or numeric summary. For the Deepwater Horizon Case Study described in Chapter 2, the response (whether a volunteer experienced adverse respiratory symptoms) is categorical. As we stated previously, summarizing the distribution of a categorical variable reduces to showing the proportion of individual subjects that fall into each of the various groups defined by the categorical variable. Figure 5.1 displays a bar chart summarizing the rate of respiratory symptoms for volunteers cleaning wildlife.
In general, it does not matter whether the frequency or the relative frequencies are reported; however, if the relative frequencies are plotted, some indication of the sample size should be provided with the figure, either as an annotation or within the caption. From the above graphic, we see that nearly 28% of volunteers assigned to wildlife experienced adverse respiratory symptoms; the graphic helps address our question, even if not definitively.
Note
When you are summarizing only categorical variables, a bar chart is sufficient. Statisticians tend to agree that bar charts are preferable to pie charts (see this whitepaper and this blog for further explanation).
While a single type of graphic (bar charts) are helpful for looking at categorical data, summarizing the distribution of a numeric variable requires a bit more thought. Consider the following example.
Example 5.1 (Paper Strength) While electronic records have become the predominant means of storing information, we do not yet live in a paperless society. Paper products are still used in a variety of applications ranging from printing reports and photography to packaging and bathroom tissue. In manufacturing paper for a particular application, the strength of the resulting paper product is a key characteristic.
There are several metrics for the strength of paper. A conventional metric for assessing the inherent (not dependent upon the physical characteristics, such as the weight of the paper, which might have an effect) strength of paper is the breaking length. This is the length of a paper strip, if suspended vertically from one end, that would break under its own weight. Typically reported in kilometers, the breaking length is computed from other common measurements. For more information on paper strength measurements and standards, see the following website: http://www.paperonweb.com
A study was conducted at the University of Toronto to investigate the relationship between pulp fiber properties and the resulting paper properties (Lee 1992). The breaking length was obtained for each of the 62 paper specimens, the first 5 measurements of which are shown in Table 5.1. The complete dataset is available online at the following website: https://vincentarelbundock.github.io/Rdatasets/doc/robustbase/pulpfiber.html
While there are several questions one might ask with the available data, here we are primarily interested in characterizing the breaking length of these paper specimens.
| Specimen | Breaking Length |
|---|---|
| 1 | 21.312 |
| 2 | 21.206 |
| 3 | 20.709 |
| 4 | 19.542 |
| 5 | 20.449 |
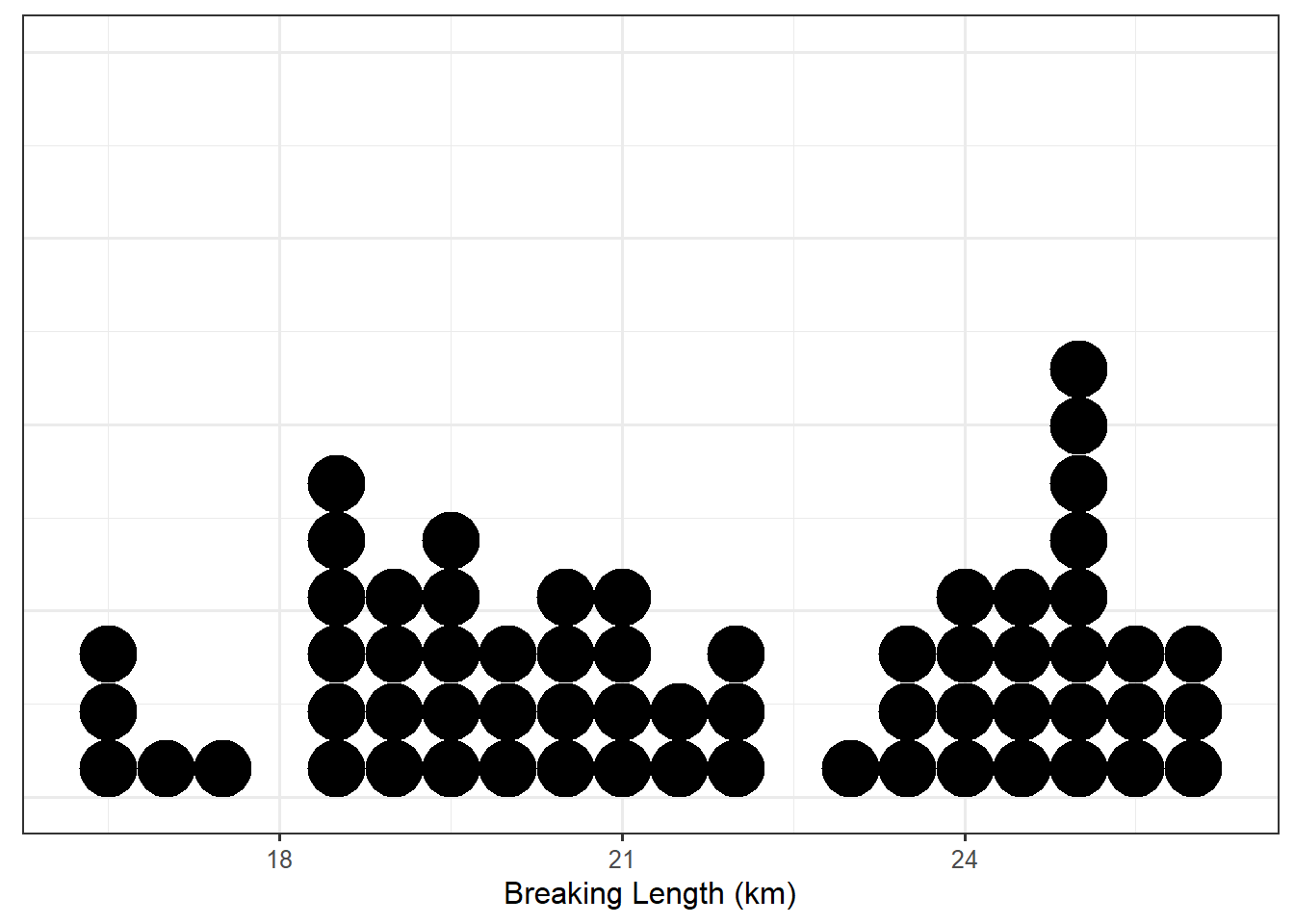
Figure 5.2 presents the breaking length for all 62 paper specimens in the sample through a dot plot in which the breaking length for each observed specimen is represented on a number line using a single dot.
With any graphic, we tend to be drawn to three components:
- where the values tend to be,
- the degree to which values tend to be clustered in a particular location, and
- the way the values tend to cluster and deviate from one another.
Notice that about half of the paper specimens in the sample had a breaking length longer than 21.26 km. Only about 25% of paper specimens had a breaking length less than 19.33 km. These are measures of location (or center, this is where the values tend to be). In particular, these are known as percentiles; the median, first quartile and third quartile are commonly used examples.
Definition 5.1 (Percentile) The \(k\)-th percentile is the value \(q\) such that \(k\)% of the values in the distribution are less than or equal to \(q\). For example,
- 25% of values in a distribution are less than or equal to the 25-th percentile (known as the “first quartile” and denoted \(Q_1\)).
- 50% of values in a distribution are less than or equal to the 50-th percentile (known as the “median”).
- 75% of values in a distribution are less than or equal to the 75-th percentile (known as the “third quartile” and denoted \(Q_3\)).
The average is also a common measure of location. The breaking length of a paper specimen is 21.72 km, on average. In this case, the average breaking length and median breaking length are very close; this need not be the case. The average is not describing the “center” of the data in the same way as the median; they capture different properties.
Definition 5.2 (Average) Also known as the “mean,” this measure of location represents the balance point for the distribution. If \(x_i\) represents the \(i\)-th value of the variable \(x\) in the sample, the sample mean is typically denoted by \(\bar{x}\).
For a sample of size \(n\), it is computed by \[\bar{x} = \frac{1}{n}\sum_{i=1}^{n} x_i.\]
When referencing the average for a population, the mean is also called the “Expected Value,” and is often denoted by \(\mu\).
Clearly, the breaking length is not equivalent for all paper specimens; that is, there is variability in the measurements. Measures of spread quantify the variability of values within a distribution (that is, the degree to which values deviate from one another). Common examples include the standard deviation (related to variance) and interquartile range. For the Paper Strength example, the breaking length varies with a standard deviation of 2.88 km; the interquartile range for the breaking length is 5.2 km.
The standard deviation is often reported more often than the variance since it is on the same scale as the original data; however, as we will see later, the variance is useful from a mathematical perspective for derivations. Neither of these values has a natural interpretation; but, when discussing measures of spread, larger values indicate a higher degree of variability in the data.
Definition 5.3 (Variance) A measure of spread, this roughly captures the average distance values in the distribution are from the mean.
For a sample of size \(n\), it is computed by \[s^2 = \frac{1}{n-1}\sum_{i=1}^{n} \left(x_i - \bar{x}\right)^2\]
where \(\bar{x}\) is the sample mean and \(x_i\) is the \(i\)-th value in the sample. The division by \(n-1\) instead of \(n\) removes bias in the statistic.
The symbol \(\sigma^2\) is often used to denote the variance in the population.
Definition 5.4 (Standard Deviation) A measure of spread, this is the square root of the variance.
Definition 5.5 (Interquartile Range) Often abbreviated as IQR, this is the distance between the first and third quartiles. This measure of spread indicates the range over which the middle 50% of the data is spread.
Note
The IQR is often incorrectly reported as the interval \(\left(Q_1, Q_3\right)\). The IQR is actually the width of this interval, not the interval itself.
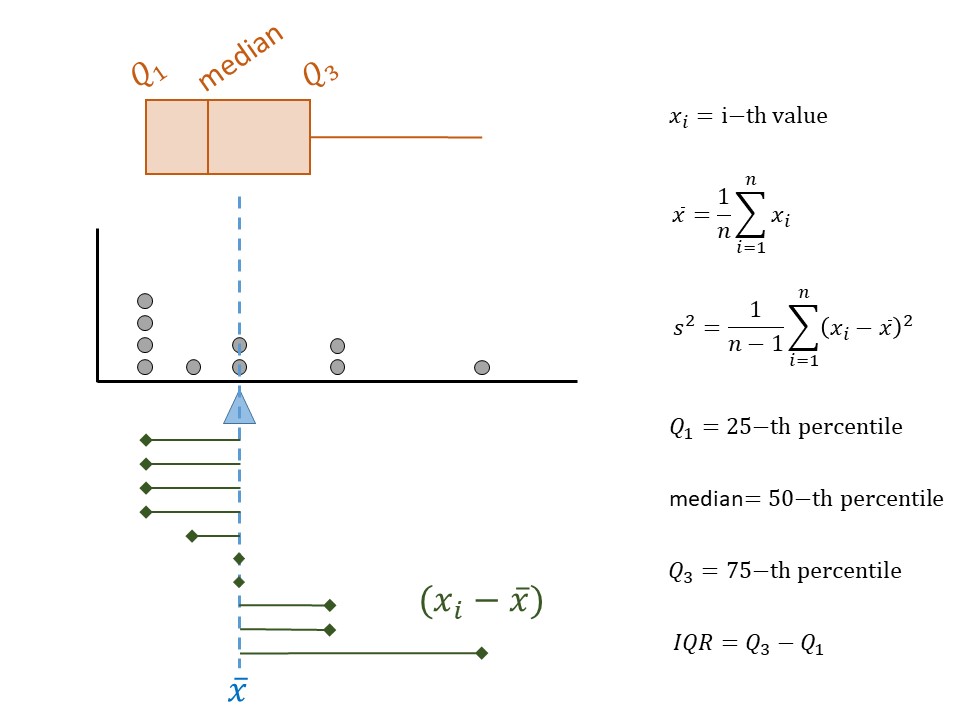
The measures we have discussed so far are illustrated in Figure 5.3. While some authors suggest the summaries you choose to report depend on the shape of the distribution, we argue that it is best to report the values that align with the question of interest. It is the question that should be shaped by the beliefs about the underlying distribution.
Finally, consider the shape of the distribution of breaking length we have observed. The breaking length tends to be clustered in two locations; we call this bimodal (each mode is a “hump” in the distribution). Other terms used to describe the shape of a distribution are symmetric and skewed. Symmetry refers to cutting a distribution in half (at the median) and the lower half being a mirror image of the upper half; skewed distributions are those that are not symmetric.
NoteDirection of Skew
We tend to focus on skew meaning not symmetric. Some authors like to describe the direction of the skew. A distribution is said to be “right skewed” (or “positively skewed”) if the spread in the upper half of the distribution is larger than the spread in the lower half of the distribution. For example, this might be indicated by the difference between the third quartile and the median being larger than the difference between the median and the first quartile.
Similarly, a distribution is said to be “left skewed” (or “negatively skewed”) if the spread in the lower half of the distribution is larger than the spread in the upper half of the distribution.
Observe that the dot plot above gives us some idea of the location, spread, and shape of the distribution, in a way that the table of values could not. This makes it a useful graphic as it is characterizing the distribution of the sample we have observed. This is one of the four components of what we call the Distributional Quartet.
Definition 5.6 (Distribution of the Sample) The pattern of variability in the observed values of a variable.
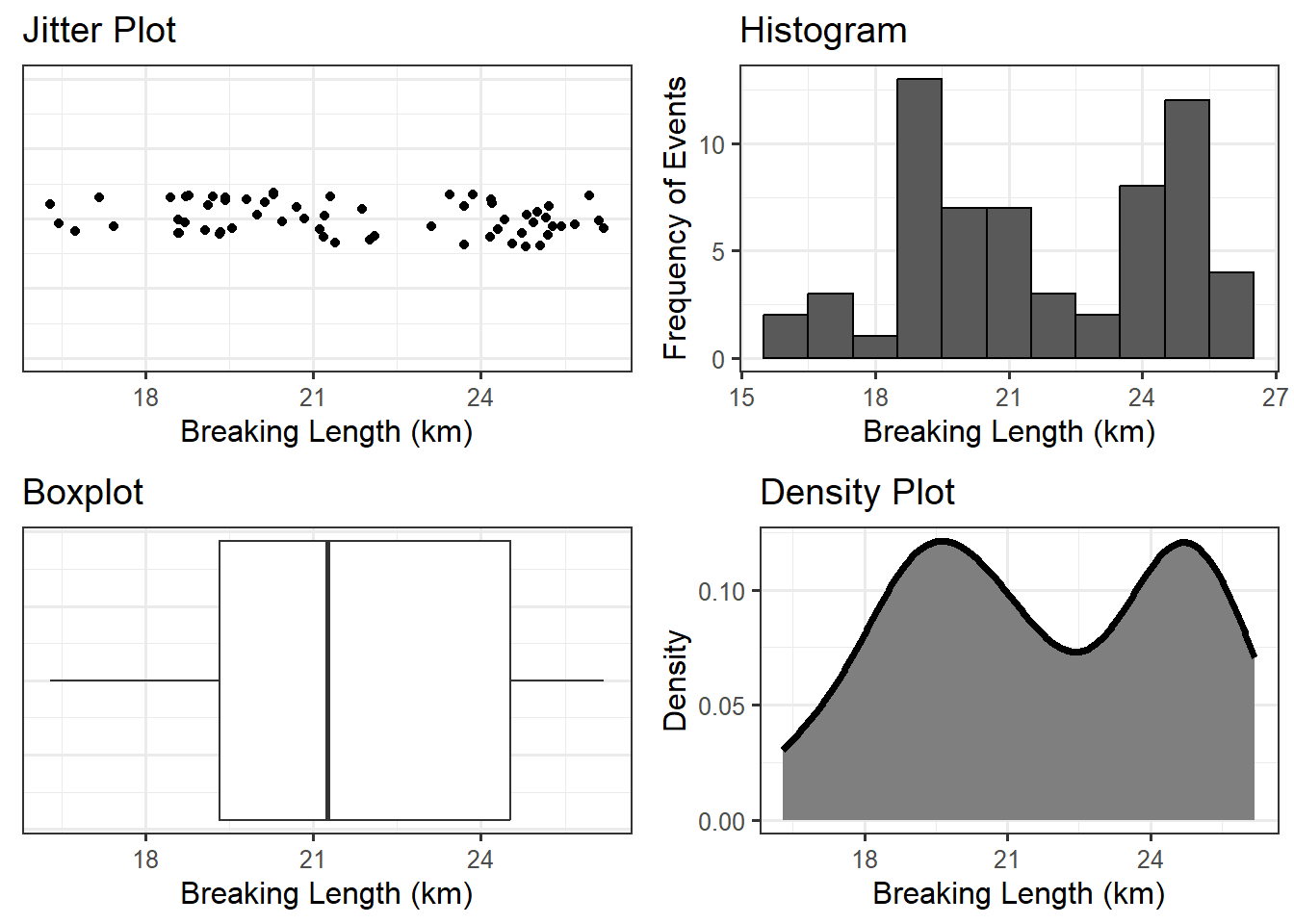
When the sample is not large, a dot plot is reasonable. Other common visualizations for a single numeric variable include:
- jitter plot: similar to a dot plot, each value observed is represented by a dot; the dots are “jittered” (shifted randomly) in order to avoid over-plotting when many subjects share the same value of the response.
- box plot: a visual depiction of five key percentiles; the plot includes the minimum, first quartile, median, third quartile, and maximum value observed. The quartiles are connected with a box, the median cuts the box into two components. Occasionally, outliers are denoted on the graphic.
- histogram: can be thought of as a grouped dot plot in which subjects are “binned” into groups of similar values. The height of each bin represents the number of subjects falling into that bin.
- density plot: a smoothed histogram in which the y-axis has been standardized so that the area under the curve has value 1. The y-axis is not interpretable directly, but higher values along the y-axis indicate that the corresponding values along the x-axis are more likely to occur.
Definition 5.7 (Outlier) An individual observation which is so extreme, relative to the rest of the observations in the sample, that it does not appear to conform to the same distribution.
To illustrate these graphics, the breaking length for the Paper Strength example is summarized using various methods in Figure 5.4. The latter three visualizations are more helpful when the dataset is very large and plotting the raw values actually hides the distribution. There is no right or wrong graphic; it is about choosing the graphic that addresses the question and adequately portrays the distribution.
The numeric summaries of a distribution are known as statistics. While parameters characterize a variable at the population level, statistics characterize a variable at the sample level.
Definition 5.8 (Statistic) Numeric quantity that summarizes the distribution of a variable within a sample.
Why would we compute numerical summaries in the sample if we are interested in the population? Remember the goal of this discipline is to use the sample to say something about the underlying population. As long as the sample is representative, the distribution of the sample should reflect the distribution of the population; therefore, summaries of the sample should be close to the analogous summaries of the population (statistics estimate their corresponding parameters). Now we see the real importance of having a representative sample; it allows us to say that what we observe in the sample is a good proxy for what is happening in the population.
Definition 5.9 (Distribution of the Population) The pattern of variability in values of a variable at the population level. Generally, this is impossible to know, but we might model it.
Statistics being a proxy for the corresponding parameter implies the mean in the sample should approximate (estimate) the mean in the population; the standard deviation of the sample should estimate the standard deviation in the population; and, the shape of the distribution of the sample should approximate the shape of the distribution of the population, etc. The sample is acting as a representation in all possible ways of the population.
TipBig Idea
A representative sample reflects the population; therefore, we can use statistics as estimates of the population parameters.
Note
Notation in any discipline is both important and somewhat arbitrary. We can choose any symbol we want to represent the sample mean. However, it is convention that we never use \(\bar{x}\) to represent a parameter like the mean of the population. The symbol \(\bar{x}\) (or \(\bar{y}\), etc.) represents observed values being averaged together. Since the values are observed, we must be talking about the sample, and therefore \(\bar{x}\) represents a statistic. A similar statement could be made for \(s^2\) (sample variance) compared to \(\sigma^2\) (population variance).
Again, in reality, the symbols themselves are not important. The importance is on their representation. Statistics are observed while parameters are not.
5.2 Summarizing Relationships
The summaries discussed above are nice for examining a single variable. In general, however, research questions of interest typically involve the relationship between two or more variables. Most graphics are two-dimensional (though 3-dimensional graphics and even virtual reality are being utilized now); therefore, summarizing a rich set of relationships may require the use of both axes as well as color, shape, size, and even multiple plots in order to tell the right story. We will explore these various features in upcoming units of the text. Here, we focus on the need to tell a story that answers the question of interest instead of getting lost in making a graphic. Consider the following question from the Deepwater Horizon Case Study described in Chapter 2:
What is the increased risk of developing adverse respiratory symptoms for volunteers cleaning wildlife compared to those volunteers who do not have direct exposure to oil?
Consider the graphic in Figure 5.5; this is not a useful graphic. While it compares the number of volunteers with symptoms in each group, we cannot adequately address the question because the research question involves comparing the rates for the two groups; that is, we are lacking a sense of how many volunteers in each group did not report symptoms.
Instead, Figure 5.6 compares the rates within each group. Note that the graphic is still reporting frequency along the y-axis; that was not the primary problem with Figure 5.5. However, by reporting frequencies for both those with respiratory symptoms and those without, we get a sense of the relative frequency with which respiratory symptoms occur.
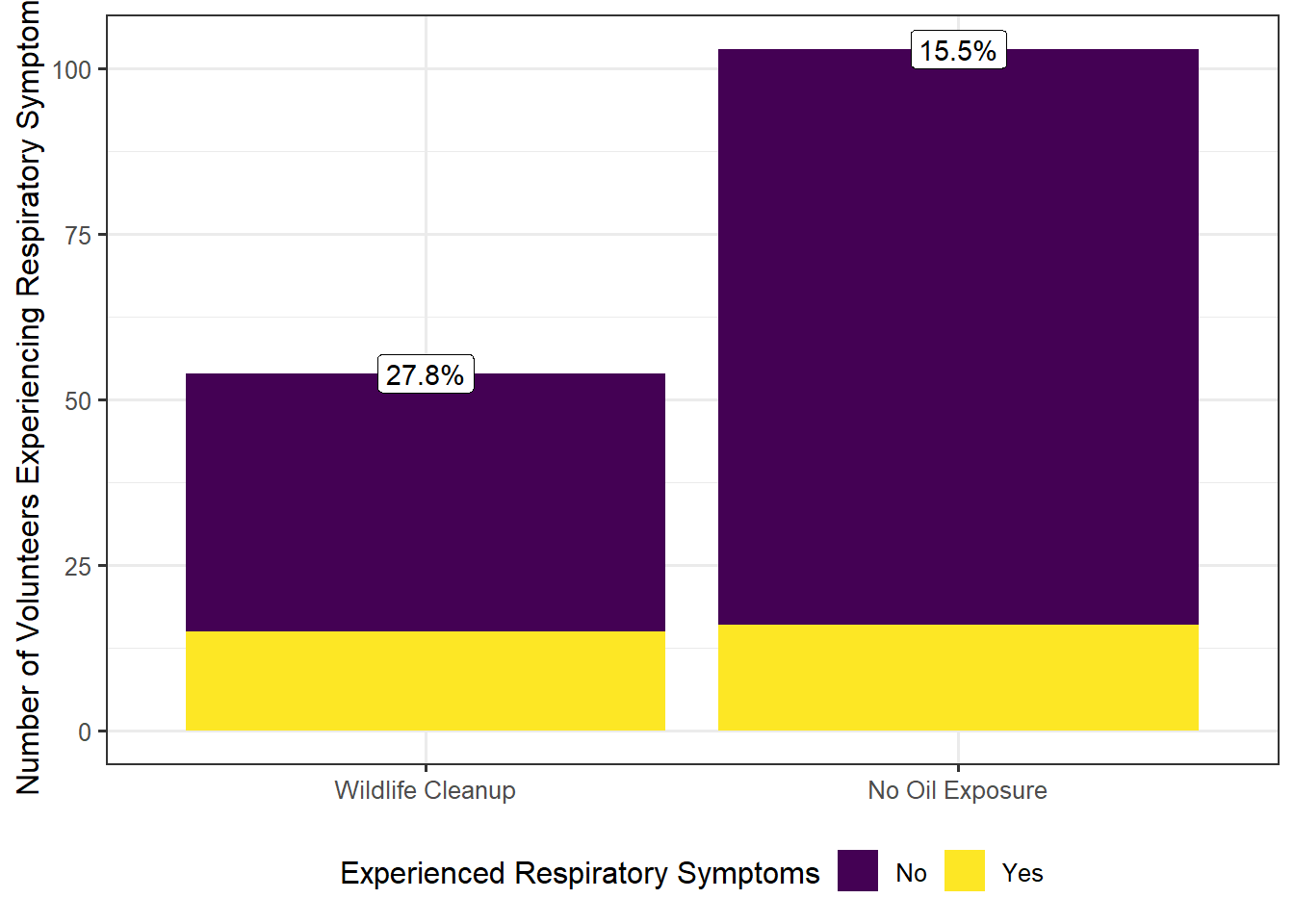
From the graphic, it becomes clear that within the sample a higher fraction of volunteers cleaning wildlife experienced adverse symptoms compared with those without oil exposure. In fact, volunteers cleaning wildlife were 1.79 times more likely to experience adverse respiratory symptoms.
The key to a good summary is understanding the question of interest and addressing this question through a useful characterization of the variability.