38 Quantifying the Evidence
In the previous two chapters, we introduced a model for describing the data-generating process for a quantitative response as a function of a single categorical predictor in the presence of blocking:
\[(\text{Response})_i = \sum_{j=1}^{k} \theta_j (\text{Group } j)_i + \sum_{m=2}^{b} \beta_m (\text{Block } m)_i + \varepsilon_i\]
where
\[ \begin{aligned} (\text{Group } j)_i &= \begin{cases} 1 & \text{if i-th observation corresponds to group } j \\ 0 & \text{otherwise} \end{cases} \\ (\text{Block } m)_i &= \begin{cases} 1 & \text{if i-th observation corresponds to block } m \\ 0 & \text{otherwise} \end{cases} \end{aligned} \]
are indicator variables.
Chapter 36 discussed obtaining estimates of these unknown parameters using the method of least squares (which turned out not to be incredibly helpful). Chapter 37 imposed conditions on the stochastic portion of the model and the block effects in order to develop a confidence interval for each parameter (again, not incredibly helpful). In this chapter, we turn to performing inference through the computation of a p-value for a set of hypotheses. Following the developments in Chapter 19 and Chapter 29, this is accomplished through partitioning variability.
Let’s return to our model for the yogurt taste rating as a function of the vendor while accounting for the correlation induced by the repeated measures across participants given in Equation 36.1:
\[ \begin{aligned} (\text{Taste Rating})_i &= \theta_1 (\text{East Side})_i + \theta_2 (\text{Name Brand})_i + \theta_3 (\text{South Side})_i \\ &\qquad + \beta_2 (\text{Participant 2})_i + \beta_3 (\text{Participant 3})_i + \beta_4 (\text{Participant 4})_i \\ &\qquad + \beta_5 (\text{Participant 5})_i + \beta_6 (\text{Participant 6})_i + \beta_7 (\text{Participant 7})_i \\ &\qquad + \beta_8 (\text{Participant 8})_i + \beta_9 (\text{Participant 9})_i + \varepsilon_i \end{aligned} \]
where we use the same indicator variables defined in Chapter 36. We were interested in the following research question:
Does the average taste rating differ for at least one of the three yogurt vendors?
This was captured by the following hypotheses:
\(H_0: \theta_1 = \theta_2 = \theta_3\)
\(H_1: \text{at least one } \theta_j \text{ differs from another}.\)
Recall that hypothesis testing is really about model comparison. The model for the data-generating process described above (and in Equation 36.1) places no constraints on the parameters; this corresponds to the alternative hypothesis. Let’s refer to this as Model 1. The null hypothesis places constraints on the parameters; namely, there are no differences in the mean response across the three groups. Enforcing the constraint suggested by the null hypothesis (with \(\theta\) representing the common unspecified value), we have a different model for the data-generating process, call it Model 0:
\[ \begin{aligned} (\text{Taste Rating})_i &= \theta + \beta_2 (\text{Participant 2})_i + \beta_3 (\text{Participant 3})_i + \beta_4 (\text{Participant 4})_i \\ &\qquad + \beta_5 (\text{Participant 5})_i + \beta_6 (\text{Participant 6})_i + \beta_7 (\text{Participant 7})_i \\ &\qquad + \beta_8 (\text{Participant 8})_i + \beta_9 (\text{Participant 9})_i + \varepsilon_i \end{aligned} \]
where again the blocking terms capture the correlation among the responses.
It turns out this set of hypotheses we are considering is more complex than we might first imagine. The null hypothesis suggests replacing the three different terms associated with vendor in the model for the data-generating process with a single common parameter while ignoring any parameters associated with the blocking. Just as in Chapter 29, the key to testing this hypothesis is to partition out the sources of variability.
Both Model 1 and Model 0 acknowledge that not all of the variability in the response is fully explained (both models have an error term). As we saw in Chapter 19, we can define the error sum of squares for a model as
\[SSE = \sum_{i=1}^{n} \left[(\text{Response})_i - (\text{Predicted Response})_i\right]^2\]
where in our case the predicted response is obtained using the parameter estimates obtained by the method of least squares. Specifically, for Model 1 above, the predicted response is given by
\[ \begin{aligned} (\text{Predicted Response})_i &= \widehat{\theta}_1 (\text{East Side})_i + \widehat{\theta}_2 (\text{Name Brand})_i + \widehat{\theta}_3 (\text{South Side})_i \\ &\qquad + \widehat{\beta}_2 (\text{Participant 2})_i + \widehat{\beta}_3 (\text{Participant 3})_i + \widehat{\beta}_4 (\text{Participant 4})_i \\ &\qquad + \widehat{\beta}_5 (\text{Participant 5})_i + \widehat{\beta}_6 (\text{Participant 6})_i + \widehat{\beta}_7 (\text{Participant 7})_i \\ &\qquad + \widehat{\beta}_8 (\text{Participant 8})_i + \widehat{\beta}_9 (\text{Participant 9})_i \end{aligned} \]
where the “hats” denote the use of the corresponding least squares estimate. If the null hypothesis is true, we would expect the amount of unexplained variability in Model 0 to be the same as the amount of unexplained variability in Model 1 \(\left(SSE_0 \approx SSE_1\right)\). That is, if the model under the null hypothesis is sufficient for explaining the variability in the yogurt test ratings, then it should perform as well as the full unconstrained model. If, however, Model 1 explains discernibly more of the variability in the yogurt taste ratings (therefore leaving less variability unexplained) than Model 0, then this would indicate the null hypothesis is false. That is, if incorporating the vendor is informative, then we would expect the amount of unexplained variability in Model 1 to be less than that of Model 0. This suggests a metric for quantifying the signal in the data:
\[SSE_0 - SSE_1,\]
where we use the subscript to denote the model from which the sum of squares was computed. As in Chapter 29, working with variance terms is easier than working with sums of squares analytically. And, we need to consider the size of the signal relative to the amount of background noise. This leads to a form of our standardized statistic:
\[\frac{\left(SSE_0 - SSE_1\right)/(k - 1)}{SSE_1/(n - k - b + 1)},\]
where again we have added subscripts to emphasize from which model we are computing the above sums of squares. In previous chapters, the degrees of freedom by which we divided were perhaps a bit more intuitive than they are here; so, we take a moment to discuss these further.
Notice that Model 1 has \(k + b - 1\) parameters (in our case, 3 parameters to capture the vendors and \(9 - 1 = 8\) parameters to capture the blocks), and Model 0 has \(b\) parameters (in our case, 1 parameter to capture the overall average for the first participant and \(9 - 1 = 8\) parameters to capture the blocks). Therefore, Model 1 is using an additional
\[(k + b - 1) - (b) = k - 1\]
parameters to explain the variability in the response. This gives the degrees of freedom used in the numerator. Now, in the full model, the predicted values require we estimate \(k + b - 1\) parameters using \(n\) observations; therefore, the degrees of freedom are
\[n - (k + b - 1) = n - k - b + 1\]
for estimating the error. This gives the degrees of freedom used in the denominator.
Definition 38.1 (Standardized Statistic for Repeated Measures ANOVA) Consider testing a set of hypotheses for a model of the data-generating process of the form (Equation 36.2):
\[(\text{Response})_i = \sum_{j=1}^{k} \theta_j (\text{Group } j)_i + \sum_{m=2}^{b} \beta_m (\text{Block } m)_i + \varepsilon_i\]
where
\[ \begin{aligned} (\text{Group } j)_i &= \begin{cases} 1 & \text{if i-th observation corresponds to group } j \\ 0 & \text{otherwise} \end{cases} \\ (\text{Block } m)_i &= \begin{cases} 1 & \text{if i-th observation corresponds to block } m \\ 0 & \text{otherwise} \end{cases} \end{aligned} \]
are indicator variables. Denote this model as Model 1, and denote the model that results from applying the parameter constraints defined under the null hypothesis as Model 0. A standardized statistic, sometimes called the “nested F statistic,” for testing the hypotheses is given by
\[T^* = \frac{\left(SSE_0 - SSE_1\right) / (k + b - 1 - r)}{SSE_1 / (n - k - b + 1)},\]
where \(k + b - 1\) is the number of parameters in the full unconstrained model and \(r\) is the number of parameters in the reduced model. Defining
\[MSA = \frac{SSE_0 - SSE_1}{k + b - 1 - r}\]
to be the “mean square for additional terms,” that captures the shift in the error sum of squares from the reduced model to the full unconstrained model, we can write the standardized statistic as
\[T^* = \frac{MSA}{MSE}\]
where the mean square error in the denominator comes from the full unconstrained model. Just as before, the MSE represents the residual variance — the variance in the response for a particular set of predictors.
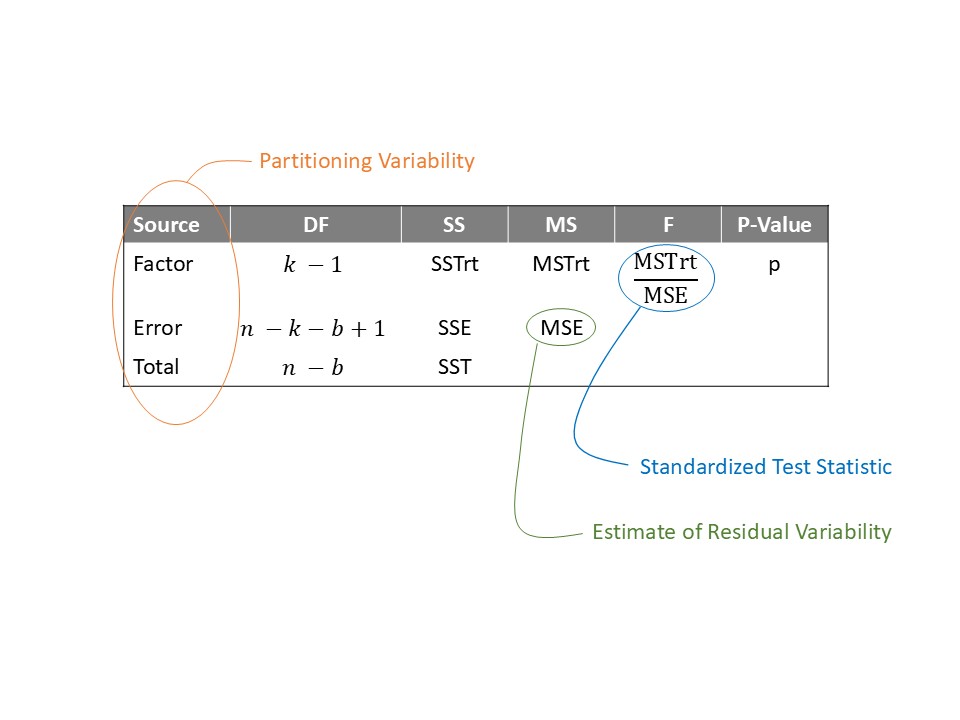
Figure 38.1 shows the tabular layout used to keep track of the various sources of variability in the most common setting — testing the null hypothesis that the mean response is the same across all levels of the factor. Here, \(MSA\) is typically called \(MSTrt\) since the additional terms in the model correspond to the terms required to allow the response to differ across the various treatment groups.
It can be shown that this standardized statistic is a special case of the one discussed in Chapter 21 and is therefore consistent with the ones presented in Chapter 19, Chapter 12, and Chapter 29. The numerator captures the signal by examining the difference between what we expect the error sum of squares to be under the null hypothesis and what we actually observe; the denominator captures the background noise (relative to the estimated mean response from the full model). Larger values of this standardized statistic indicate more evidence in the sample against the null hypothesis.
We should not lose sight of the fact that our standardized statistic is really a result of partitioning the variability and considering the variability explained by adding the factor of interest to the blocks, relative to the noise in the response. Underscoring that the standardized statistic is a result of this partitioning, the analyses of these sources of variability is often summarized in an ANOVA table.
Note
Occasionally, an ANOVA table for repeated measures ANOVA will partition the variability in terms of the variability due to the factor, the variability due to the blocks, and the error variability. We have instead presented the ANOVA table as corresponding to a specific set of hypotheses.
TipBig Idea
Comparing the difference in the unexplained variability between two models allows us to assess if the data is inconsistent with the simpler of the two models.
Just as before, given data, we can compute not only the standardized statistic but a corresponding p-value. As with any p-value, it is computed by finding the likelihood, assuming the null hypothesis is true, of getting, by chance alone, a standardized statistic as extreme or more so than that observed in our sample. “More extreme” values of the statistic would be larger values; so, the area under the null distribution to the right of the observed statistic is the p-value. Of course, the model for the null distribution is developed under the conditions we place on the stochastic portion and the block effects in the model for the data-generating process.
Let’s return to the question that inspired our investigation in this chapter:
Does the average taste rating differ for at least one of the three yogurt vendors?
This was captured by the following hypotheses:
\(H_0: \theta_1 = \theta_2 = \theta_3\)
\(H_1: \text{at least one } \theta_j \text{ differs from another}.\)
Table 38.1 gives the ANOVA table summarizing the partitioned sources of variability in the yogurt taste ratings. We have a large p-value (computed assuming the data is consistent with the classical repeated measures ANOVA model). That is, the sample provides no evidence to suggest the average yogurt taste rating differs across any of the vendors. While we cannot prove that the average ratings are the same for all vendors, this study is consistent with the three yogurt vendors having the same taste ratings, on average. This is in line with the idea that consumers were paying a premium for the experience of going to a yogurt-shop; they viewed the product similarly with what could be purchased at a local grocery retailer.
| Term | DF | Sum of Squares | Mean Square | Standardized Statistic | P-Value |
|---|---|---|---|---|---|
| Vendor | 2 | 2.889 | 1.444 | 0.319 | 0.731 |
| Error | 16 | 72.444 | 4.528 | ||
| Total | 18 | 75.333 |
TipBig Idea
Determining if a response is related to a categorical predictor in the presence of blocking is done by determining if the factor explains a discernible portion of the variability in the response, above and beyond the variability explained by the blocks.
In this chapter, we partitioned variability as a way of evaluating the strength of evidence the factor of interest plays in determining the response. As with the ANOVA model, partitioning the variability is a key step. By partitioning the variability in the response, we are able to construct a standardized statistic for testing the hypothesis of interest. The model for the null distribution of this statistic depends upon the conditions we are willing to impose on the stochastic portion of the data-generating process. Regardless of the conditions we impose, we can interpret the resulting p-value similarly. It provides an indication of whether the data suggests that the average response differs for at least one of the groups.
Of course, the interpretation of the p-value depends on the conditions we impose. We should not choose such conditions without performing some type of assessment to ensure those conditions are reasonable — that the data is consistent with the conditions. That is the focus of the next chapter.